Automatiser l’intégration de factures avec FME

On associe souvent FME à sa capacité à traiter des sources de données complexes telles que les données vectorielles 2D et 3D, les images ou le Lidar, mais l’automatisation de tâches simples est un autre domaine où excelle notre logiciel favori.
L’automatisation des tâches répétitives permet d’augmenter la productivité et de réduire les erreurs, mais c’est aussi un bon moyen pour affecter des ressources humaines à des tâches plus stimulantes et à plus forte valeur ajoutée.
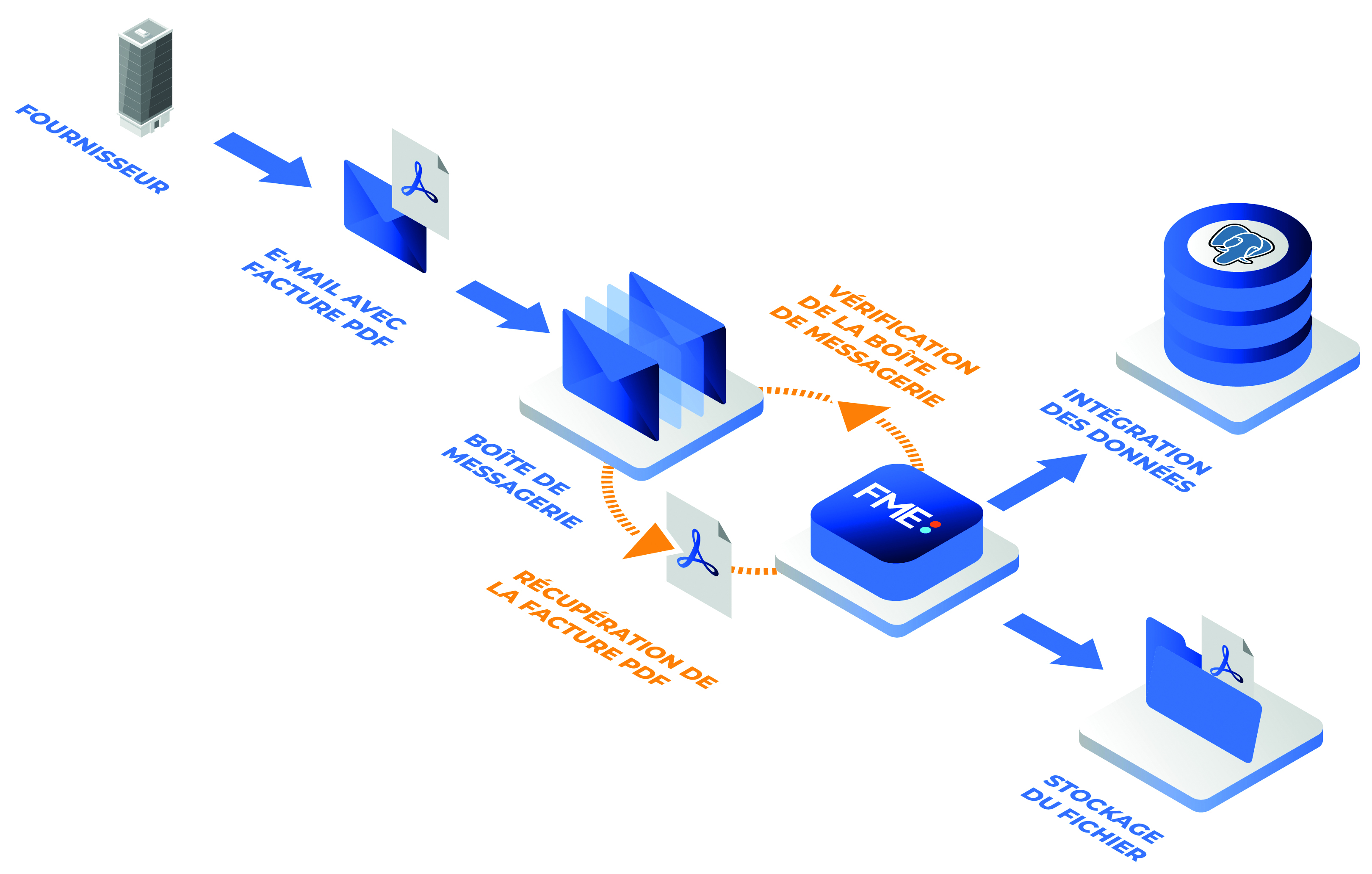
Pour répondre à ses propres besoins, Veremes a ainsi développé un système assurant la lecture et l’intégration des factures fournisseurs dans sa base de données commerciale. Il permet de remplacer une tâche manuelle de réception d’e-mail, ouverture de pièce jointe, contrôle et saisie prenant entre cinq et vingt minutes. Le nouveau mécanisme repose sur une instance FME Flow hébergée dans le cloud AWS, et un traitement de type Automation qui permet de traiter les documents transmis par e-mail à plusieurs fournisseurs.
Fonctionnement de l’Automation
L’automatisation commence dans le système de messagerie Microsoft Exchange par l’identification des messages contenant des factures et leur routage vers une boîte e-mail partagée dédiée à l’exploitation par FME Flow.
Le traitement par FME est assuré par une Automation dont le point d’entrée est un déclencheur de type Email – IMAP qui interroge la boîte de réception toutes les dix minutes. Le fonctionnement asynchrone d’IMAP a été privilégié à un traitement en temps réel basé sur SMTP : IMAP est apparu plus robuste en cas d’interruption de service et plus facile à gérer pour simuler des envois en phase de test.
Lorsqu’un nouvel e-mail est détecté, la propriété « Email Subject » du message est exploitée pour identifier le fournisseur et orienter la suite du workflow vers la branche du traitement adaptée au traitement du modèle de facture correspondant. La propriété « Sent from address » peut sembler plus adaptée mais elle ne convient pas à la réalisation de tests ni aux traitements annexes tels que la reprise de l’historique.
Ensuite, le traitement FME correspondant au bon type de facture est exécuté. Ce traitement assure l’extraction des informations, leur contrôle et leur chargement dans une base PostgreSQL. La facture au format PDF est archivée dans un bucket AWS S3. Si le traitement échoue, un e-mail est envoyé à l’administrateur afin de l’alerter du problème.
Traitement par lots
Un seul e-mail peut contenir plusieurs factures. Pour gérer cette situation, l’Automation exécute un traitement parent ExecutionMultifichiers, qui lance autant de fois le traitement enfant « unitaire » qu’il y a de fichiers à traiter. Le traitement unitaire fait partie du projet publié sur FME Flow, mais n’apparaît pas dans le design de l’Automation. Le Transformer FMEFlowJobSubmitter du traitement ExecutionMultifichiers va appeler le traitement unitaire. Les paramètres publiés du traitement unitaire sont renseignés dans le FMEFlowJobSubmitter.
A noter
L’utilisation de FMEFlowJob-Submitter est pratique pour réaliser des tests dans FME Form mais elle masque la complexité du traitement. Nous recommandons plutôt d’enchaîner les traitements au niveau de l’Automation pour faciliter la maintenance.
Pour cela, il faut utiliser un Writer de type FME Flow Automations en sortie du traitement FME Form parent et ajouter une deuxième action dans l’Automation pour traiter les fichiers individuels.
Lecture de la facture au format PDF
Plusieurs façons de lire un fichier PDF sont possibles. L’option « Spatial » permet de considérer le contenu du document comme des vecteurs localisés dans le document.
Les coordonnées des différents éléments vont servir pour filtrer les différentes parties de la facture qui sont toujours formatées de la même manière, comme l’en-tête, les désignations de produits, etc.
Le texte est interprété de la même façon qu’une étiquette, qui comporte des attributs très utiles tels que le point d’insertion, la chaîne de caractères, la taille du texte.
Extraction d’information
De manière générale, il faut utiliser les expressions régulières avec StringSearcher pour rechercher la signification de chaque texte : nom de produit, montant, date, numéro de facture…
Il est également très utile d’exploiter les coordonnées pour identifier les libellés qui sont situés sur une même ligne ou une même colonne et une même page. On peut également exploiter des attributs de format permettant de repérer rapidement certains textes par leur taille ou police.
Stockage des données
Après avoir reconstitué les informations contenues dans le document, une série de contrôles est effectuée pour vérifier que les informations sont cohérentes et que la facture n’a pas déjà été enregistrée.
Les données peuvent alors être envoyées vers la base de données PostgreSQL cible et le document PDF stocké sur S3 grâce à S3Connector.
Traçabilité des opérations
Pour assurer la traçabilité des opérations, une table “chargement” est mise à jour à chaque fois qu’une facture est intégrée dans la base, en détaillant la date et l’heure, le nom du fichier et l’utilisateur qui a lancé le traitement (“FME Flow” ou éventuellement l’utilisateur qui a lancé FME Form pour une exécution semi-automatique).
Bilan et perspectives
La solution mise en place a permis un retour sur investissement très rapide, inférieur à un an.
FME Flow permet d’assurer de manière robuste le traitement des documents réceptionnés sous forme de pièce jointe. Le mode Automation a été utilisé pour lire les boîtes de messagerie et orienter chaque message vers un traitement spécifique tout en alertant un administrateur en cas d’anomalie.
Le traitement des fichiers PDF est très performant mais sa conception est relativement complexe et doit être adaptée à chaque type de document. La méthode employée dans cet article est bien adaptée au traitement en masse de documents basés sur une structure stable.
L’apparition des IA génératives apporte de nouvelles possibilités au traitement de documents dont la structure est variable ou peu connue. FME propose d’ores et déjà plusieurs solutions pour faire appel à ce type de service tout en respectant la confidentialité des données et les contraintes réglementaires (RGPD).