Enrichissez votre expérience de FME avec Python

Pourquoi et comment implémenter Python dans un traitement FME ? Quels sont les avantages et les gains de performances envisageables ? Cet article vous présente exemples et conseils pour répondre à ces questions.

Python est un langage de programmation universel orienté sur la création d’objets/entités. Il est très largement utilisé pour créer sites web et logiciels, mais également pour automatiser des tâches ou encore effectuer des analyses de données. Cette adaptabilité et polyvalence lui permettent d’être employé par tout corps de métier, du programmeur au statisticien, en passant par l’utilisateur moyen désireux de créer des jeux de données.
FME permet de traiter des centaines de formats et dispose de centaines de Transformers pour vous aider à manipuler vos données. Ceci dit, un peu de Python peut parfois débloquer des situations complexes ou simplifier des scripts FME encombrés et difficiles à maintenir.
Comment intégrer un script Python dans un traitement FME ?
FME intègre nativement plusieurs versions de l’interpréteur Python, il n’y a donc aucune installation spécifique à prévoir pour exécuter du code Python.
Si vous avez besoin de librairies spécifiques, il suffit de copier le fichier .py correspondant dans le répertoire \python de votre installation de FME ou encore plus simplement avec l’utilitaire pip.
Deux Transformers vous permettront de saisir votre code :
- PythonCreator pour exécuter une unique fois le code Python indépendamment du flux de données
- Et surtout PythonCaller qui exécute le code Python pour chaque entité du flux, donnant ainsi la possibilité d’exploiter les informations attributaires et géométriques
Pour en savoir plus sur l’utilisation de Python dans FME nous vous invitons à consulter l’excellent tutorial (en anglais) de Safe Software à ce sujet : Python and FME Basics.
Augmenter les capacités de FME
Quelques lignes de Python permettent de doter FME de nouvelles capacités : machine learning avec les librairies PyTorch ou TensorFlow, big data avec Pandas ou production de graphique (Plotly, Matplotlib, seaborn…)
Prenons un exemple concret dans le domaine de l’analyse statistique : l’ANOVA (ANalysis Of VAriance). Il s’agit d’un test statistique basique permettant de comparer les variances de moyennes entre plusieurs groupes. Ce test est utile si l’on cherche à évaluer l’effet d’un ou plusieurs facteurs sur un ensemble mesuré.
Cas d’étude : vous êtes en charge de tester l’efficacité de différents engrais sur la croissance d’une famille de plantes. Ayant plusieurs engrais en main de nature différente nommés “A”, “B”, et “C”, vous pourrez utiliser un test ANOVA afin de découvrir s’il existe une différence significative entre la croissance de vos groupes testés. Ici, l’ANOVA sera dite one-way car un seul facteur d’effet est mesuré (nature de l’engrais).
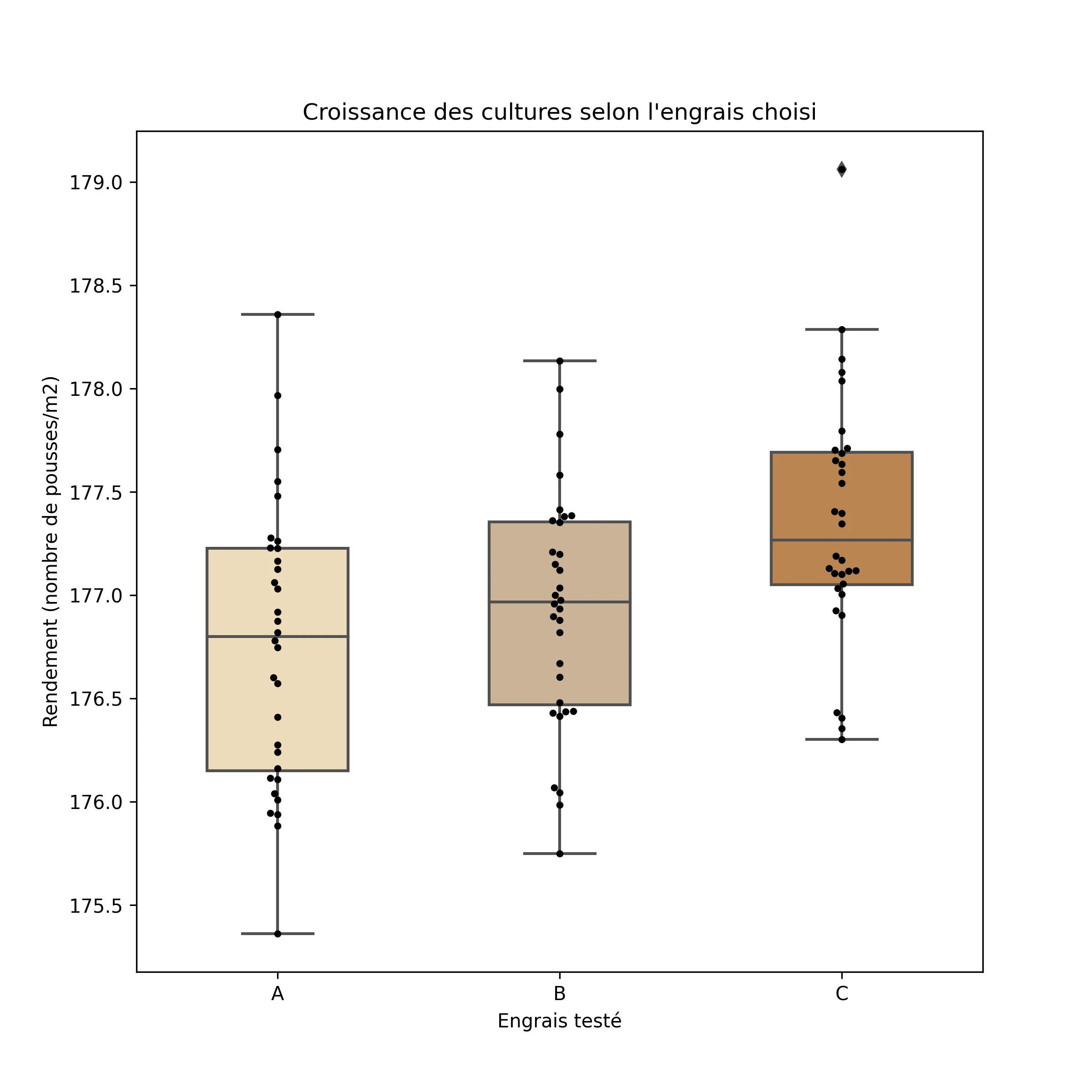
Avant d’effectuer l’analyse, il est intéressant d’utiliser FME pour récupérer les résultats et les préparer en vue du test. Lorsque les entités du flux sont prêtes à être testées, un PythonCaller est utilisé afin d’exécuter l’analyse. On pourra utiliser les libraires de création de graphiques afin d’observer la répartition de nos valeurs avant d’exécuter les tests.
Réaliser une one-way ANOVA sous Python est chose aisée : il suffit d’importer ‘f_oneway’ à partir de ‘scipy.stats’ (ou autre package similaire). Le résultat du test est significatif : il y a donc bien une différence de rendement entre les groupes testés (à 95% de confiance). Ce résultat peut être sorti du PythonCaller et intégré dans le traitement afin de poursuivre l’analyse.
Afin de déterminer lequel des engrais est le plus efficace, une analyse supplémentaire est effectuée (pour les curieux : test post-hoc de Tukey afin de croiser les résultats entre les groupes “A-B”, “A-C” et “B-C” pour déterminer la significativité à l’échelle individuelle – librairie bioinfokit). Les résultats de l’analyse suggèrent que l’engrais “C” est le plus efficace à 95% de confiance.
Il est donc possible de sortir ce résultat du PythonCaller et de l’intégrer dans le traitement afin de ne sélectionner que cet engrais et de poursuivre la transformation de données.
Améliorer les performances et la maintenabilité
On peut également choisir d’utiliser Python pour simplifier un traitement FME et le rendre plus concis et plus facile à maintenir et dans certains cas pour améliorer ses performances. Certains traitements manipulent de nombreuses chaînes de caractères pour faire des opérations simples (découpage de texte, remplacement, concaténation…). L’opération est aisée sous FME mais peut être laborieuse et le projet final compliqué à maintenir s’il contient des dizaines de Transformers.
L’utilisation d’un PythonCaller peut permettre de remplacer des dizaines de Transformers et ainsi d’augmenter la lisibilité et la maintenabilité du script. Dans ce cas, l’opération peut améliorer légèrement les performances mais ce n’est pas systématique et ce n’est pas l’objectif recherché.
Cependant, il est des cas où l’utilisation de code peut diminuer sensiblement les temps de traitements et faciliter le développement. Les cas les plus fréquents concernent l’exploitation des attributs de type liste, le travail sur les noms d’attributs, les boucles et la récursivité.
Imaginons un traitement de migration de données : une base de données existante contenant de nombreuses tables doit être convertie selon un nouveau formalisme. Les conditions des changements pour chaque attribut seront détaillées dans un fichier dit de mapping. FME offre une solution en permettant de créer des listes d’attributs puis de les éclater (ListExploder). Opérations anodines pour de petits jeux de données mais qui peut consommer beaucoup de mémoire et de temps de calcul sur les gros jeux de données.
L’appel à un code Python peut simplifier la conception et augmenter la rapidité du traitement en remplaçant les listes FME par des dictionnaires et exploitant les capacités du langage pour la gestion de boucle.


Il n’y a pas que le Python dans la vie !
FME ne fait pas la part belle qu’à Python : d’autres langages sont gérés par l’application, tels que R.
R est un langage de programmation semblable à Python, dont l’utilisation est entre autres centrée autour des statistiques. On pourra, à l’image du PythonCaller, placer un RCaller dans un traitement à condition d’avoir installé R dans le répertoire d’installation de FME.
Une question de dosage
Vouloir remplacer tous les Transformers par des PythonCaller n’est certainement pas une bonne idée mais il serait dommage de se passer de la puissance d’un tel outil sans connaître ses capacités.
Pour les débutants, nous vous conseillons de faire vos premiers pas sur des cas simples tels que le traitement de chaînes de caractères ou des calculs numériques. Pour les plus expérimentés, il faut se rappeler que les scripts doivent être maintenables par vos collègues et que le choix des outils dépend également de la culture de développement Python dans votre organisme.