Traiter les données distantes avec FME

FME offre une grande liberté dans la manière de traiter les données et, dans de nombreux cas, plusieurs solutions s’offrent au développeur. De manière générale on peut considérer que l’architecture la plus efficace et performante consiste à traiter les données « là où elles sont » en évitant si possible les transferts sur le réseau. Voici quelques conseils pour le traitement des données distantes.
FME et les données… en base de données
Pour extraire des informations d’une base de données et les transformer en fichier ou les charger dans une autre base, la solution la plus simple consiste à lire les tables de la base source dans FME, puis à traiter ces données en réalisant les opérations nécessaires (jointure, jointure spatiale, contrôle qualité, filtre) à l’aide des Transformers et enfin à écrire le résultat produit dans le format cible.
Si les données à traiter ne représentent qu’un faible pourcentage des données initiales présentes en base, il est sans doute possible d’améliorer les performances de manière significative en faisant travailler la base de données plutôt que FME.
Jointure dans FME… ou en base de données ?
Les Transformers de jointure disponibles dans FME (FeatureMerger et FeatureJoiner) nécessitent de lire l’ensemble des données dans FME au préalable.
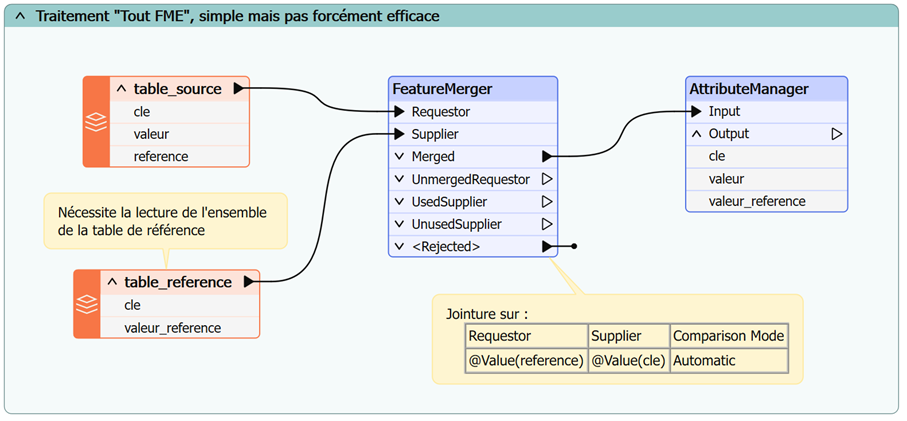
Si la table de référence contient de nombreux enregistrements, sa lecture complète est pénalisante et il sera préférable de recourir à un DatabaseJoiner.
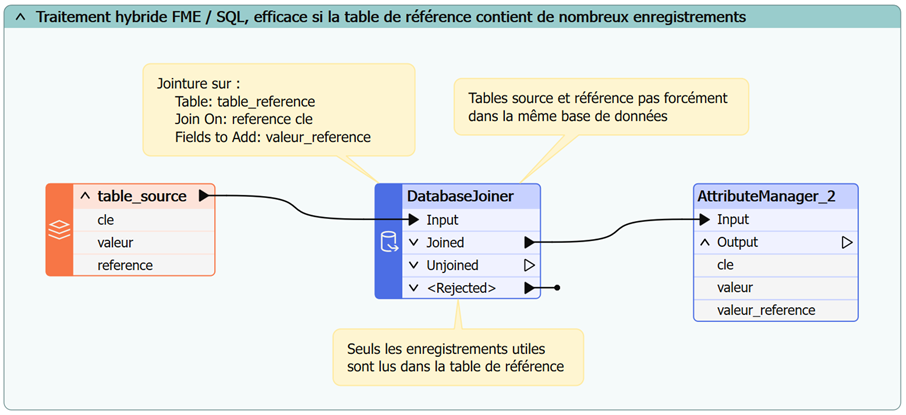
Si les tables appartiennent à la même base de données (et que vous n’êtes pas allergique à l’écriture d’une ligne de code SQL 😊), vous pouvez directement réaliser la jointure dans la base de données et exploiter son résultat dans FME. Cela sera encore plus efficace puisque la base de données pourra s’appuyer pleinement sur ses indexes pour comparer les enregistrements.
Qu’est-ce qu’un index ? Pour une base de données, un index est un mécanisme accélérateur de recherche, de façon similaire à la table des matières d’un document qui permet d’accéder plus rapidement à une section spécifique.

Notez que SQL permet de réaliser des opérations bien plus élaborées qu’une simple jointure, autorisant la mise en œuvre d’algorithmes complexes basés sur le parcours de graphe, la récursivité ou toute librairie de fonctions disponibles sur votre base de données (par exemple PostGIS ou pgRouting pour PostgreSQL).
Une application ludique de résolution de Sudoku grâce à la récursivité a ainsi été présentée durant la Conférence FME 2020 (vidéo de Loïc Guénin-Randelli et Frédéric Eichelbrenner, « Rester zen avec SQL »), mais des applications bien plus sérieuses peuvent être réalisées avec la même technique, telles que l’aide au dimensionnement de réseaux de fibres optiques par exemple.
Filtrage dans FME… ou en base de données ?
Lorsque les données lues en base doivent être filtrées pour n’en conserver qu’un sous-ensemble, lire la totalité de la table dans FME avant de sélectionner ce sous-ensemble (par exemple avec un Tester) n’est pas très efficace.
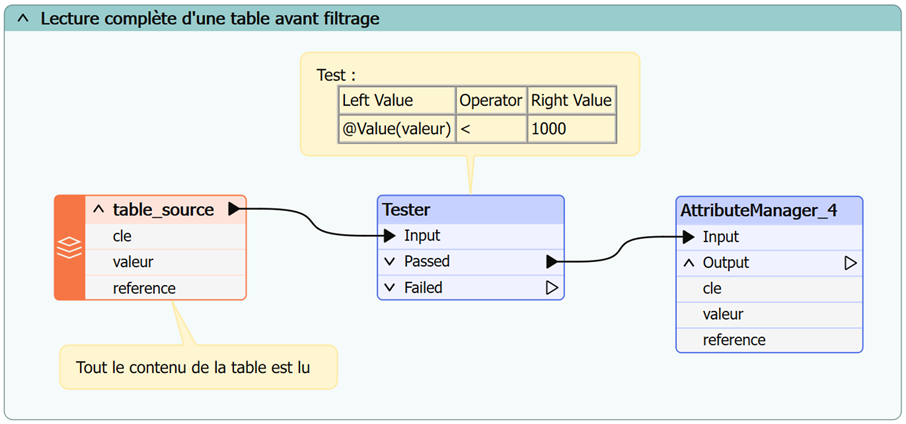
Remplacez la séquence comprenant la lecture de données en base, puis des filtres (Tester, StringSearcher, …) par un Reader exploitant le paramètre « Clause Where ».

Si les enregistrements à lire doivent correspondre à une restriction géographique (emprise d’intérêt, limite administrative, …), plutôt que lire la totalité des données puis employer un SpatialFilter, il est préférable d’utiliser un FeatureReader, qui permet de combiner filtrage spatial et attributaire.

FME et l’accès aux données distantes
Fichiers directement accessibles par une URL
FME permet depuis de nombreuses années de lire directement des jeux de données en spécifiant une URL plutôt qu’un chemin sur son poste de travail ou sur son réseau local.
Dans ce cas, à chaque exécution, FME télécharge le jeu de données vers un répertoire temporaire de façon transparente pour l’utilisateur, avant d’envoyer les entités vers la suite du traitement. Cela présente le double avantage d’éviter une étape manuelle de téléchargement et de disposer automatiquement de la dernière version publiée du jeu de données. Cela peut cependant être pénalisant lorsque le traitement doit être lancé plus fréquemment que le jeu de données n’est mis à jour.
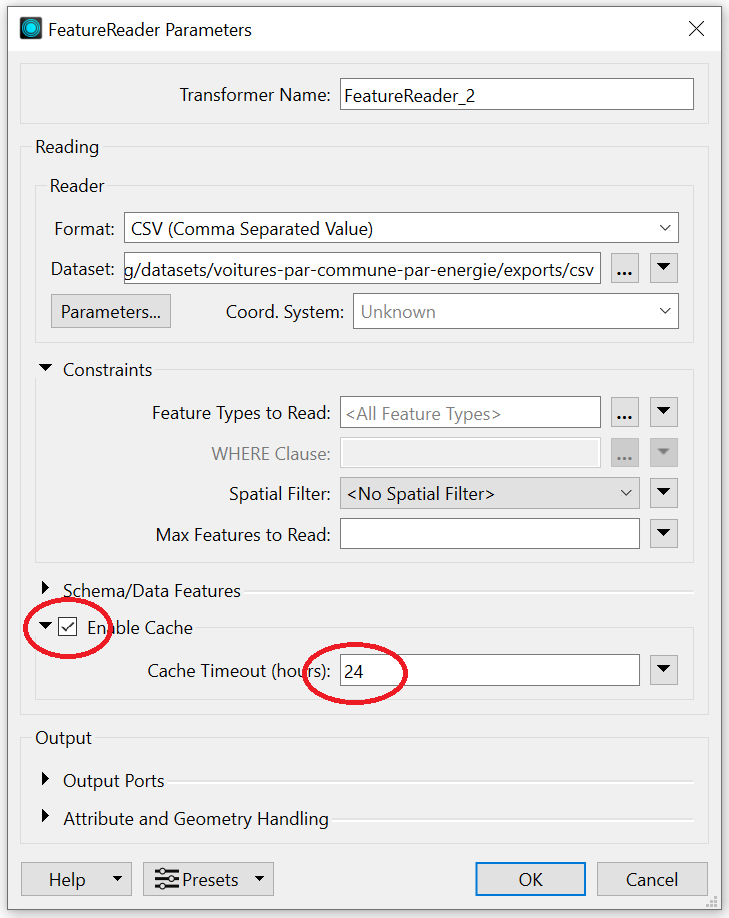
Vous pouvez cependant limiter le nombre de téléchargements en activant dans le FeatureReader un « cache » spécifique dont la durée de validité peut être réglée à votre convenance.
Données accessibles via un service normalisé
FME permet également d’exploiter des services d’accès aux données tels que WFS par exemple.
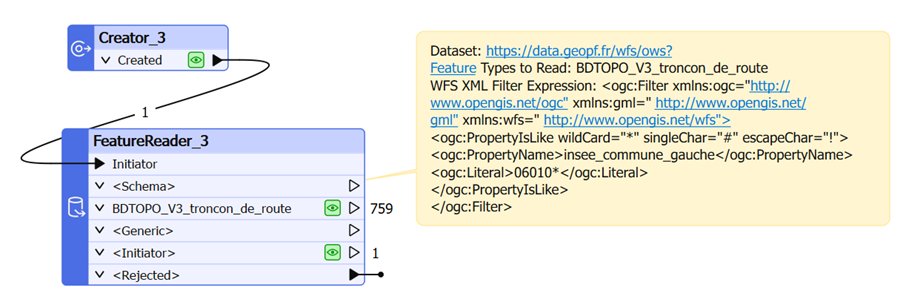
Dans ce cas de figure, le principe n’est pas de récupérer l’entièreté du flux de données (ici par exemple les tronçons de la BDTOPO représentant plusieurs centaines de milliers de routes), mais un sous-ensemble pertinent pour la problématique à traiter.
Il est alors primordial de paramétrer le Reader ou FeatureReader avec un filtre pour limiter la recherche selon des propriétés d’attributs, comme ici par exemple le code INSEE.
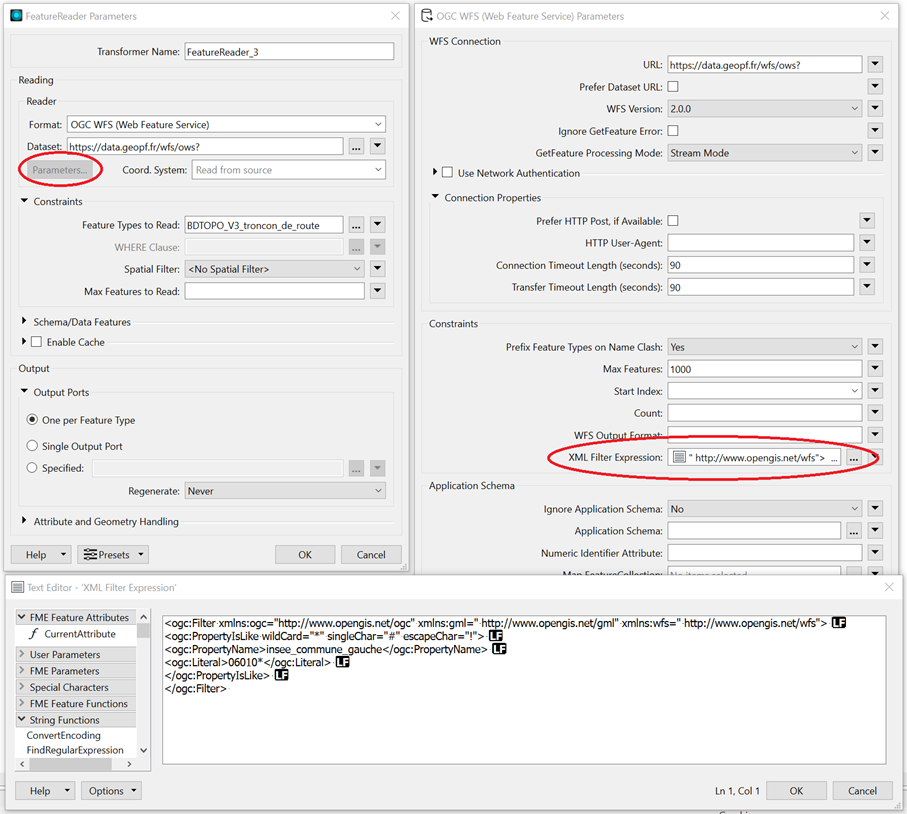
La syntaxe du filtre dépend évidemment du format de lecture, dont il vous faudra consulter la documentation et réaliser quelques tests pour élaborer ce filtre, mais vous récupérerez certainement largement le temps investi dans vos recherches.
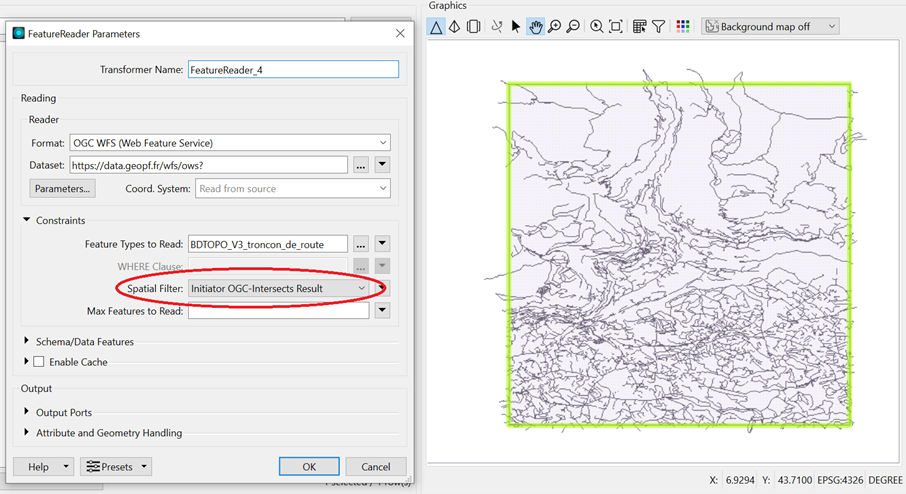
Veuillez noter que, suivant les formats, le filtre spatial proposé par l’interface du FeatureReader peut s’appliquer avant ou après récupération des données du service, ce qui peut impacter fortement le résultat lorsque le service limite le nombre d’objets retournés. Dans le cas du format WFS, depuis la version FME 2023, le filtre spatial du FeatureReader est bien passé au serveur avant la récupération des données, ce qui permet de récupérer facilement les données souhaitées.
Données accessibles via une API
Une API (Application Protocol Interface) est un protocole de communication qui régit le dialogue entre l’application cliente (ici FME) et le serveur offrant un service.
Dans le cas où l’API est suffisamment populaire, il est fréquent que FME dispose déjà d’un Transformer qui gère tous les aspects du dialogue avec le serveur. L’utilisateur FME n’a alors pas à s’occuper des « détails techniques » et peut directement employer le « Connector » adapté au service. Tous les Connectors fonctionnent selon le même principe, intégrant l’authentification, l’identification du container de données, et permettant le listage du contenu, le téléchargement (download), le téléversement (upload), et la suppression des données distantes.
Pour une API moins populaire, l’utilisateur FME doit gérer lui-même le dialogue avec un enchaînement de Transformers HTTPCaller entrecoupés de JSONFragmenter / JSONFlattener ou de XMLFragmenter / XMLFlattener suivant le langage de communication proposé par le service. Le décodage des informations véhiculées en JSON ou XML pouvant nécessiter quelques subtilités, ce sujet fera l’objet d’une communication spécifique ultérieurement.
FME et les données… dans le Cloud
On entend ici par Cloud un système de type « Platform As A Service » proposant à la fois le stockage de données et la mise à disposition de machines virtuelles permettant l’hébergement d’applications.
Lorsque les données sont stockées dans le cloud, que ce soit sous forme de fichiers ou de bases de données, il est recommandé de les exploiter avec une instance FME située dans le même datacenter pour améliorer les performances mais aussi pour diminuer la consommation d’énergie correspondant au transport des données.
Dans certains cas (Amazon Web Services par exemple), on peut également ajouter un argument économique car le traitement local des données permet d’éviter les coûts d’extraction des données. A noter que FME Flow Hosted peut être une solution intéressante pour des traitements ponctuels de données stockées dans les régions AWS où ce service est présent (Dublin, Francfort, Londres…).
L’accès en lecture ou écriture à des systèmes de stockage par objet tels que AWS S3 ou Azure Blob Storage constitue un cas particulier. Il est nécessaire d’utiliser S3Connector ou AzureBlobStorageConnector pour réaliser les opérations de listage, lecture et écriture et échanger des fichiers avec son disque local. Si les volumes de données échangés sont importants, l’utilisation d’une instance FME dans la même région Cloud doit également être privilégiée.
On peut cependant mettre un bémol au principe de favoriser le rapprochement du traitement et des données. En effet, depuis quelques années, des formats de nouvelle génération tirent parti de la capacité offerte par le protocole HTTP d’accéder à une partie seulement d’un fichier distant sans imposer son téléchargement complet.
Dans le cas d’une orthoimage de grande taille par exemple (pouvant facilement peser quelques dizaines de Gigaoctets), le format Cloud-Optimized-Geotiff ou COG permet d’exploiter une portion d’une image distante tout en minimisant les transferts réseaux. De plus, la puissance de calcul nécessaire à l’extraction de la portion d’image désirée incombe au client et non au serveur, ce qui est un gage de robustesse du système lorsque le nombre d’accès concurrents croît.
Selon le même principe, sont apparus les formats Cloud-Optimized-Point-Cloud ou COPC pour le stockage des nuages de points (souvent issus de capteurs LIDAR), ZARR pour le stockage de tableau de résultats multidimensionnels et Seek-Optimized-Zip ou SOZip pour stocker des fichiers de tout type. FME prend déjà en compte en lecture et écriture les formats COG, COPC et ZARR.